
GenAI-sovellusten suojamekanismit
Posted on 30.9.2024 by Topi Santakivi
Generatiivisen tekoälyn kehitys etenee edelleen hurjaa vauhtia. Kielimallien päättelykyky kasvaa jatkuvasti, ja niiden käyttöön liittyvät kustannukset laskevat. Hintojen laskiessa tulee taloudellisesti kannattavammaksi rakentaa uusia ratkaisuja ja integroida niitä olemassa oleviin tuotteisiin.
Miksi kielimalleja hyödyntävä sovellukset tarvitsevat suojamekanismeja (guardrails)? Kuten aiemmin kirjoitin, kielimallit ovat mestareita hallusinoimaan. Jos mallin vastausten halutaan perustuvan dokumentteihin ja faktoihin, on oltava tapa tarkistaa, että näin myös käy.
Lisäksi on tärkeää varmistaa, ettei mallin päälle rakennettua sovellusta pysty käyttämään vääriin tarkoituksiin, mikä tarkoittaa, ettei sovelluksen aihealueista ajauduta liian kauas ja pidetään huolta siitä, ettei sovelluksesta saa kyselemällä irti käyttäjälle kuulumatonta tietoa.
Kielimalleja hyödyntävien sovellusten suojaaminen on yhdistelmä perinteisiä tietoturvaperiaatteita (esim. pääsynhallinta, turvallinen verkkoinfra, salaukset, kooditason tarkistukset, tietoturvatestaus & auditointi) sekä kielimalleille tarkoitettuja mekanismeja, joita käsittelemme tässä kirjoituksessa.
Kielimalleille tarkoitetut suojamekanismit voidaan jakaa kahteen kategoriaan: kielimalliin sisäänrakennettuihin sekä sovelluksessa oleviin mekanismeihin. Sisäänrakennetut mekanismit rakennetaan malleja kehittävien tekoäly-yhtiöiden toimesta.
Sovelluksessa olevia suojamekanismeja voi toteuttaa eri tavoin ja riippuen siitä, kuinka “pitäviä” niiden tulee olla. Tähän vaikuttavat esimerkiksi sovelluksen käyttötarkoitus, käyttäjämäärä sekä se, onko kyseessä sisäinen vai ulkoinen sovellus. Kahden käyttäjän sisäinen työkalu tarvitsee erilaiset suojaukset kuin 500 käyttäjän julkinen chatbot.
Kielimalliin sisäänrakennetut suojamekanismit
Kielimalliin sisäänrakennettu suojamekanismi tarkoittaa käytännössä sitä, miten malli on koulutettu vastaamaan haitallisiin syötteisiin. Tämä on yhdistelmä mallin koulutusdatan suodatusta ja ohjattua oppimista. Koulutusdatasta voidaan siistiä pois sisältöä, jota mallin ei haluta omaksuvan, ja ohjatun oppimisen vaiheissa näytetään esimerkkien avulla, miten mallin tulisi vastata erilaisiin kysymyksiin.
Yksi viimeisimmistä kehitysaskelista on OpenAI:n huhtikuussa 2024 julkaisema Instruction Hierarchy -menetelmä, jossa kielimalli opetetaan priorisoimaan järjestelmäkehotteen (system prompt) ohjeita käyttäjän antamaa syötettä korkeammalle. Vaikka tämäkään ei ole täysin vedenpitävä menetelmä, mallin kyky vastata kieltävästi paranee huomattavasti aiempiin lähestymistapoihin verrattuna. OpenAI:n kielimalleista GPT-4o-mini on ensimmäinen, joka sitä hyödyntää.
Sovellukseen rakennetut suojamekanismit
Sovellukseen rakennetut suojamekanismit voidaan jakaa kahteen kategoriaan: syötettä käsitteleviin ja ulostuloa käsitteleviin mekanismeihin. Syötteiksi lasketaan tässä käyttäjän syöte, kielimallille syötettävä data, sekä hakutulokset ja kielimallin käyttämien työkalujen vastaukset.
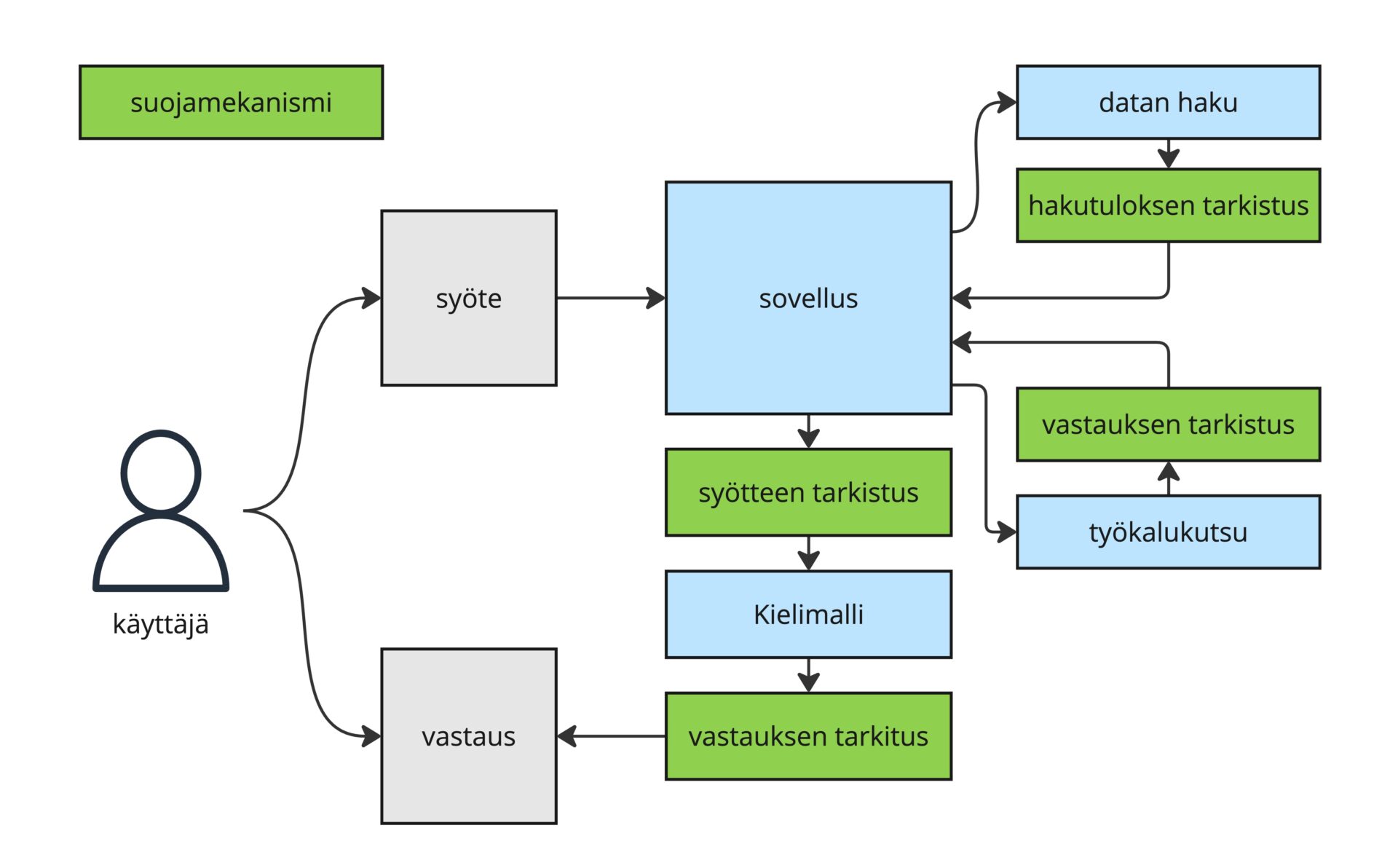
Syötettä käsittelevät suojamekanismit
Kielimallille tulevan syötteen, etenkin käyttäjän syötteen, käsittely on suojausten keskeisimmässä roolissa. Mitä enemmän kielimallia on integroitu eri suuntiin, ja varsinkin jos sen vastauksiin pohjautuen tallennetaan dataa jonnekin, sitä suurempi merkitys syötteen käsittelyllä on.
Syötteen käsittelyn tarkoituksena on pitää keskustelu aiheessa, vastata asianmukaisesti sopimattomaan sisältöön, sekä suojautua yrityksiltä saada sovellus toimimaan ei-halutulla tavalla. Jälkimmäisestä johtuvia virheitä ei turhaan kutsuta nimellä syöteinjektio (prompt injection, vrt. SQL injection), eivätkä ne myöskään sattumalta ole OWASP Top 10 for LLM Applications -riskilistan kärjessä.
Syöteinjektio tarkoittaa sitä, että kielimallille annetussa syötteessä on sisältöä, joka saa mallin vastaamaan sovelluksen näkökulmasta väärällä tai ristiriitaisella tavalla. Tämä voi tarkoittaa esimerkiksi vääriä tai haitallisia ohjeita ja toimintaa, tai ylipäätään vastausta, joka ei millään tavalla liity sovellukseen.
Syötettä käsittelevän suojamekanismin perusidea on tunnistaa haitalliset syötteet ennen kuin ne pääsevät kielimallille asti. Syötteestä voidaan pyrkiä tunnistamaan esimerkiksi kirosanat, käyttäjän tarkoitusperä, pysyminen halutussa aihealueessa, sekä se, sisältääkö syöte salaista tai henkilökohtaista tietoa.
Ulostuloa käsittelevät suojamekanismit
Ulostuloa käsittelevät suojamekanismit toimivat samalla periaatteella kuin syötettä käsittelevät, mutta syötteen sijaan tarkoituksena on käsitellä kielimallin tuottamaa vastausta ennen kuin se annetaan käyttäjälle.
Ulostulon käsittelyllä voidaan esimerkiksi pyrkiä tunnistamaan vastaukseen eksynyt salainen tieto tai järjestelmäkehotteen (system prompt) “vuotaminen”. Lisäksi voidaan arvioida vastauksen laatua ja relevanssia tai muokata sen rakennetta haluttuun muotoon.
Suojamekanismien toteuttaminen
Suojamekanismeja voidaan toteuttaa monilla eri tavoilla: ohjeistamalla, hyödyntämällä kielimallia, koodaamalla, tai käyttämällä aiheeseen tarkoitettuja kirjastoja.
Suojamekanismit ohjeistamalla
Yksinkertaisin taso suojauksissa on antaa kielimallille ohjeita siitä, miten toimia ja vastata. “Olet avustaja, jonka tehtävänä on vastata käyttäjälle asioista X, Y, ja Z. Vastaa tällä ja tällä tyylillä, ja pyri pitämään keskustelu aiheissa A, B ja C. Jos et tiedä vastausta johonkin, kerro se käyttäjälle”.
Tämän päivän kielimallit, kuten Claude 3.5 Sonnet, GPT-4o ja 4o-mini, pystyvät jo varsin hyvin seuraamaan annettuja ohjeita ja pitäytymään aiheessa. Pelkillä ohjeilla siis pääsee melko pitkälle, mutta myös tiukempia suojauksia on usein tarpeellista rakentaa.
Suojamekanismit kielimallin avulla
Suoraviivainen keino nostaa suojaustasoa on kierrättää syöte toisen kielimallin läpi ennen kuin se menee varsinaisen vastauksen muodostavalle mallille. Esimerkiksi GPT-4o-mini on riittävän nopea, kyvykäs ja edullinen, jotta siltä voi saada toimivan arvion siitä, mitkä ovat käyttäjän aikeet ja kuinka oleellinen käyttäjän esittämä kysymys on. Vastaavasti ulostulonkin voi vielä tarkistuttaa kielimallilla ennen käyttäjälle vastaamista.
On olemassa myös suojaamisen hienosäädettyjä kielimalleja, kuten Metan Llama Guard. Hienosäädetty kielimalli voi toimia hyvinkin tehokkaasti tehtävässään, mutta sen kääntöpuoli on, että tehokkuus riippuu hienosäädössä käytetystä datasta. Esimerkiksi Llama Guard toimii hyvin suojaamiseen, mutta lähinnä englanninkieliselle syötteelle.
Kirjastot
Yksi tapa toteuttaa suojamekanismit on ottaa käyttöön aiheeseen tarkoitettu kirjasto, kuten Guardrails AI tai Nvidian NeMo Guardrails. Molemmista löytyy kattavat työkalut erilaisten suojausten toteuttamiseen. Kirjastojen suurin ero on siinä, että NeMo Guardrails keskittyy enemmän keskustelevien sovellusten ja koko keskusteluflow:n hallintaan, kun taas Guardrails AI:sta löytyy työkaluja yksittäisten tarkistusten toteuttamiseen eri puolille sovellusta.
Yhteenveto
Tarvittavien suojamekanismien valitseminen on tasapainoilua mahdollisten uhkien ja käytettävyyden välillä. Pelkillä ohjeilla suojattu sovellus on nopea vastaamaan, mutta saattaa riittävästi houkuteltuna eksyä sivuraiteille. Vastaavasti kaikki mahdolliset suojaukset sisältävä sovellus voi pitää käyttäjän aisoissa, mutta vastauksessa voi kestää kauemmin. Miten tätä tasapainoa sitten hallitaan? Se vaatii pala palalta kehittämistä ja systemaattista testausta, mutta siitä lisää seuraavalla kerralla.